최근에 공개된 Text-to-Video(TTV) 앱들을 모아 둔 사이트를 발견했다.
https://mpost.io/7-best-text-to-video-ai-generators-powerful-and-free/
10+ Best Text-to-Video AI Generators: Powerful and Free
Want to easily create funny videos from any description? You should then experiment with AI video generation tools. Unquestionably, AI is the future. AI
mpost.io
우연히 Youtube에서 AI로 생성된(AI generated) 패러디 및 유머 영상들을 발견하면서 "그럼 나도 한번 체험해볼까?"라고 생각해서 이런 사이트를 찾게 됐다.
공개된 사이트 중 무료체험을 할 수 있는 사이트는 소수.
그마저도 길어야 수 초에 달하는 동영상을 출력하는 게 전부이다.
그중에서도 ModelScope을 체험하기로 했다.
위 사이트에 따르면, Alibaba 소속의 분과가 해당 앱을 개발했다고 한다.
https://huggingface.co/spaces/damo-vilab/modelscope-text-to-video-synthesis
ModelScope Text To Video Synthesis - a Hugging Face Space by damo-vilab
huggingface.co
Seed, 프레임 수, Inference step 수를 정하고서
"The Korean president dances with Godzila"라는 프롬프트를 넣으니...

어디서 많이 본 체형과 옷차림의 두 사람 형상이 나타나 신나게 춤을 춘다. ㅎ
한국 관련한 프롬프트에 대해선 형상의 질이나 관련성이 현저히 떨어지는 걸 다른 AI 기반 앱에서도 볼 수 있었다.
아마도 한국 관련된 이미지/영상 데이터의 양이 한정되어서 그런 듯하다.
페이지 하단에 보니 웬 걸?
AI 기계를 훈련시키기 위해 사용된 공적 데이터셋(public datasets)의 이름이 나와있다.
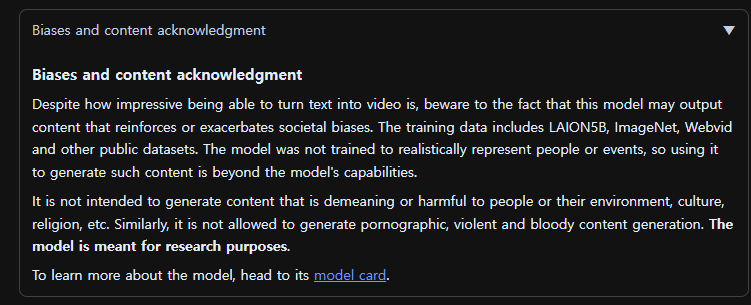
LAION5B, ImageNet, Webvid...
https://github.com/LAION-AI/
LAION AI
This is the repo of LAION, a non-profit organization to liberate machine learning research, models and datasets. - LAION AI
github.com

LAION AI GitHub 페이지에는 프로젝트팀이 독일에 위치하고 있다고는 하나
참여자들의 프로필을 보면 루마니아, 미상의 국가, 영국이라고 표기되어 있다.
https://www.image-net.org/about.php
ImageNet
www.image-net.org
ImageNet의 경우, 영미권 대학교 교수진이 주도하는 팀이 dataset 관리에 관여하고 있다.

https://m-bain.github.io/webvid-dataset/
Large Scale Text-Video Dataset
Containing 10M text-video pairs crawled from the web.
m-bain.github.io

Webvid 프로젝트 팀 또한 마찬가지이다.
위 페이지가 마음에 드는 건 Dataset을 어떻게 생성했는지 간략한 도식과 설명문이 공개되어 있다는 점이다.

https://arxiv.org/pdf/2104.00650.pdf
WebVid-2M 영상-텍스트 pretraining 모델에 사용된 데이터를 수집하는 방법으로 다음을 소개하고 있다:
The data was scraped from the web following a similar procedure to Google Conceptual Captions (CC3M). We note that more than 10% of CC3M images are in fact thumbnails from videos, which motivates us to use such video sources to scrape a total of 2.5M text-video pairs.
약 250만개의 텍스트-영상쌍(pair)들을 수집(scrape)해서 모델을 만들었다고 한다.
영상 출력물에서 드러나는, 편향성으로 비춰질 수도 있는 프롬프트와 영상 간의 낮은 관련성은 나로 하여금 스크래핑 방식에 대한 궁금증을 자아냈다. 그러나 상기 문서 그 어디에서도 그에 대한 답을 찾을 수 없었다.
데이터 수집 방식이 균형 잡히지 않았다는 의혹만을 남긴 채 이번 조사를 마쳐야겠다.
'Computer > AI' 카테고리의 다른 글
| [GPT] Prompt: Futurism 문구 (0) | 2023.06.06 |
|---|---|
| [GPT] Lexica - 특정 이미지에 대한 프롬프트에 쓰일 키워드 제안 사이트 (0) | 2023.06.05 |
댓글